How Persly uses LangGraph and LangSmith to deploy only evaluated healthcare agents
Persly is a healthcare AI chatbot built to help patients and caregivers understand trustworthy medical information in a clear, accessible way. After short clinic visits, Persly's users often return home with a long list of unresolved questions—about test results, treatment options, side effects, and prognosis. The more serious the condition, the more information they need, yet the time and opportunity to ask follow-up questions is limited.
In this situation, many patients turn to search engines or general-purpose AI chat services such as ChatGPT. However, in healthcare, even a single explanation with an unclear source or missing context can cause significant confusion and anxiety. Generative AI can produce plausible-sounding answers quickly, but determining whether an answer is truly reliable—and safe for a specific patient's situation—is a fundamentally different problem. Manually verifying every response is not scalable.
To address this, Persly is designed not as a simple answer-generating AI, but as a medical agent that analyzes questions, gathers evidence, and verifies its own responses. Persly's agent combines the reasoning capabilities of large language models with source-enforced RAG and a self-critique-based workflow.
In this post, we share why Persly chose LangGraph and LangSmith, how we designed a medical agent on top of them, and the lessons we learned from operating it in a real production environment.
Why We Built Persly
In clinical settings, the amount of time patients spend face-to-face with their physicians continues to decrease. At the same time, the volume of information patients are expected to understand keeps growing. This imbalance becomes even more pronounced for patients with serious or complex conditions.
Within a short appointment, it is difficult to fully grasp the meaning of test results, available treatment options, potential side effects and prognosis, and what needs to be prepared for the next steps.
Many patients only realize their questions after leaving the exam room. There was not enough time to ask, and once they return home and start searching for answers, they are confronted with conflicting explanations and information from unclear or unreliable sources—often leading to even greater confusion.
Persly was born from this problem.
In a reality where time with doctors is shrinking while the amount of information seriously ill patients need is growing, we asked a simple but critical question: could there be a way to explain trustworthy medical information in a form patients can truly understand? That question marked the beginning of Persly's medical agent.
Hallucinations and Trust in Medical Answers
Large language models are powerful, but they have clear limitations in medical contexts. A model can almost always produce fluent, plausible-sounding text, yet plausibility does not equate to trustworthiness. In healthcare, even a small error or a missing piece of context can directly affect a patient's judgment and decisions.
The core issue is that this limitation is not simply a matter of model capability. Medical answers must take into account the questioner's condition, medical history, current context, and reliable evidence—all at the same time.
However, the more we attempt to force all of these factors into a single generation step, the more likely the model is to blend in unsourced general knowledge or produce information that drifts beyond the given context. This is the well-known problem of hallucination.
In medical AI, hallucinations are not merely a quality issue; they represent a safety-critical failure mode. "Mostly correct explanations" or "general cases" are not sufficient. The system must clearly distinguish, for the specific user—or patient—what can be said and what should not be said under their particular conditions.
For Persly, this led to a clear conclusion: relying on a single-step generation approach cannot simultaneously guarantee accuracy and trustworthiness in medical answers. As a result, Persly does not treat hallucination as a problem to be fixed after the fact, but as a core design challenge that must be prevented structurally.
How Does the Persly Agent Produce High-Trust Medical Answers?
Persly prioritizes safe, evidence-based answers far more than "fast responses." For that reason, it does not generate an answer in a single step, and only advanced agents that pass rigorous evaluation are deployed.
When Persly receives a question, the agent first redefines the problem. Instead of jumping straight to "what to say," it structures what the question is actually asking for. At this stage, the agent organizes the following:
- Core requirements that must be included in the answer
- Constraints derived from the user's condition or context
- Safety-critical red flags
- Missing information that cannot be inferred from the current question (open questions)
These elements become the baseline criteria for every downstream node, guiding how the answer is produced and revised. Once the requirements are defined, the agent must ground each requirement in reliable medical information. In Persly, RAG is not an optional enhancement—it is a system-level prerequisite. Evidence is collected under the following principles:
- Search only when necessary
- Restrict retrieval to official, trustworthy medical sources (e.g., national public health authorities, CDC, and NIH-affiliated institutions)
- In later stages, do not allow the model to use information outside the retrieved context
This is not merely a decision to improve accuracy. It is a deliberate design choice to constrain the answer space so that self-critique becomes verifiable.
During drafting, the Persly agent uses only the following inputs:
- The requirements and constraints defined upfront
- Medical evidence collected through RAG
- Context accumulated from the user's prior conversation history
Even if the model may "know" general medical facts from training, it does not include them unless they are present in the provided context. This constraint enables the self-critique stage to explicitly verify whether the draft relied on any information outside the allowed context.
Self-Critique: Verifying the Answer Internally
Once a draft is generated, the Persly agent does not return it immediately. Instead, it moves into a self-critique stage, where the agent explicitly evaluates its own output by asking the following questions:
- Have all requirements been satisfied?
- Was only information consistent with the provided context used?
- Were any safety-critical red flags overlooked?
- Does the answer contain information outside the context—that is, hallucinations?
This self-critique is an evaluation process that produces concrete revision instructions. If the outcome indicates that the answer is "not yet ready," the Persly agent returns to the revision step. The agent then revises the draft by directly applying its own critique and reassesses whether the result meets the standard for a trustworthy medical answer.
This critique → revise loop follows the iterative refinement patterns proposed in recent research, but Persly extends the approach with real-world medical service constraints in mind. Specifically, it enforces:
- Upper bounds on the number of iterations and response latency
- Critique priorities that place medical safety above all else
- A strict rule that unsourced information is not permitted, even during revision loops
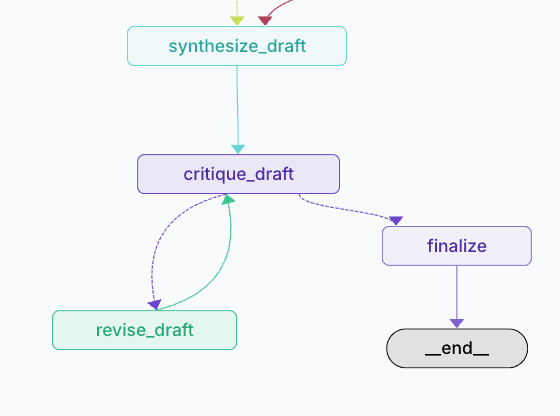
Why LangGraph: The Persly Agent Must Be Stateful by Design
Persly's agent is not a simple pipeline that executes multiple steps in sequence. Trustworthy medical answers emerge from a process in which decisions lead to revisions, revisions feed back into judgment, and the history of those decisions influences subsequent evaluations.
Persly's self-critique operates as follows:
- Generate draft A
- Produce critique C for draft A
- Revise draft A using critique C → A′
- Critique the revised draft
- Repeat as needed
This is clearly a stateful process. If implemented in a stateless manner, the system would need to re-inject information such as the current iteration count, previously identified issues, and already-resolved errors into the model input at every step. That approach inevitably increases cost, inflates context size, and raises the risk of new errors.
The same applies to red-flag detection. In medicine, red flags are not single, isolated checks, but rather a cumulative set of risk signals. Some risks may not be apparent in the initial question and only emerge after follow-up questions or clarifications. How the system has already responded to detected red flags also determines what can or cannot be said next.
A medical agent must therefore continue reasoning while maintaining state: previously detected red flags, safety warnings already issued, and newly surfaced risk conditions. This requirement pushed Persly beyond a collection of stateless calls and toward a stateful machine with explicit state transitions.
LangGraph fits this requirement precisely. By modeling the agent as a state graph composed of nodes and edges, Persly can represent each decision step as an independent node and manage success, failure, and retry paths as explicit state transitions.
LangGraph Architecture
As a result, Persly's medical agent is not "a chain that runs once and ends," but a system that remembers state and accumulates judgment over time.
Only Agents That Pass Evaluation Are Deployed
Persly incorporates agent-level evaluation and deployment gating into its internal workflow.
Every Persly agent must pass all internal thresholds across the full set of metrics provided by OpenEvals within the following evaluation pipeline before it can be deployed:
- Publicly released USMLE sample exam questions (309 questions, curated for evaluation)
- A proprietary cancer-focused QA dataset built in-house (~10,000 QA pairs)
- HealthBench-hard (1,000 questions)
These evaluations are fully automated through a LangSmith-based pipeline. All datasets are continuously updated in collaboration with domain experts, and the USMLE benchmark is curated from the latest publicly available questions.
 LangSmith Evaluation Pipeline
LangSmith Evaluation Pipeline
 LangSmith Dashboard
LangSmith Dashboard
For example, even if an agent achieves high accuracy, it will not be deployed to production if its groundedness score fails to meet the required threshold. Instead, the agent is sent back for further refinement. This approach extends iterative refinement beyond academic experimentation and into the product lifecycle itself—an area rarely addressed in research papers.
Closing Thoughts
Recent research increasingly agrees on one point: LLMs are evolving away from systems that produce answers in a single pass, toward architectures that review and revise their own outputs. Persly follows this direction, but asks a more practical question:
What additional safeguards are required to operate this structure safely in the real world of healthcare?
Our answer was to embed the following directly into the system:
- RAG with sentence-level source enforcement to ensure trust
- Critique criteria specialized for the medical domain
- Quantitative, evaluation-driven deployment gating
This is how Persly approaches medical AI—not as a research prototype, but as a production-grade system designed for real-world use.
Ready to try Persly?
Get trustworthy medical answers backed by verified sources. Persly helps patients and caregivers navigate health information with confidence.