Evidence-Governed RAG in Healthcare: Why Persly Controls Retrieved Evidence Instead of Skipping It
RAG(Retrieval-Augmented Generation) has become the de facto standard architecture for LLM-based AI. In healthcare especially, it is treated as a baseline design choice to reduce hallucinations and incorporate up-to-date information.
Yet most RAG systems share an implicit assumption:
Always perform retrieval for every query and pass the results directly to the generation step.
Persly goes one step deeper than this assumption.
Is retrieval always necessary?
Or more precisely,
Are all retrieved documents always safe and appropriate?
Persly's answer is not "let's reduce retrieval," but rather:
Let's govern the retrieved evidence.
Why Is Always-On Retrieval a Problem?
RAG is generally understood as a technique that improves accuracy. In the medical domain, however, something matters more than "whether retrieval was performed."
Was the retrieved document appropriate?
1. Conflicting Standards Across Documents (Retrieval-Induced Inconsistency)
For example,
"What is the maximum daily dose of acetaminophen for adults?"
The retrieval results may contain a mix of:
- Differing national guidelines
- Pediatric dosing documents
- Outdated guidelines
The LLM may attempt to synthesize these and produce an answer that blends conflicting standards or over-qualifies its response with excessive conditions.
2. Plausible but Inaccurate Documents (Retrieval-Induced Hallucination)
There is no guarantee that top-ranked documents are always high quality.
- Blog-style health articles
- Outdated guidelines
- Information applicable only to specific patient populations
- Documents from a different jurisdiction
Because LLMs tend to treat retrieved documents as strong evidence when generating answers, a single inappropriate document can contaminate the entire response.
3. Excessive Context Distorts Medical Reasoning
"I think the diarrhea is caused by a medication I recently started taking."
The core of this question is triage. But if lengthy guidelines or statistical data are injected directly, the model may generate an unnecessarily complex differential diagnosis.
In healthcare, over-explanation can increase patient anxiety or undermine trust.
Persly's Approach: We Don't Skip Retrieval. We Govern It.
Persly does not choose an architecture that skips retrieval.
Instead, we design the following structure:
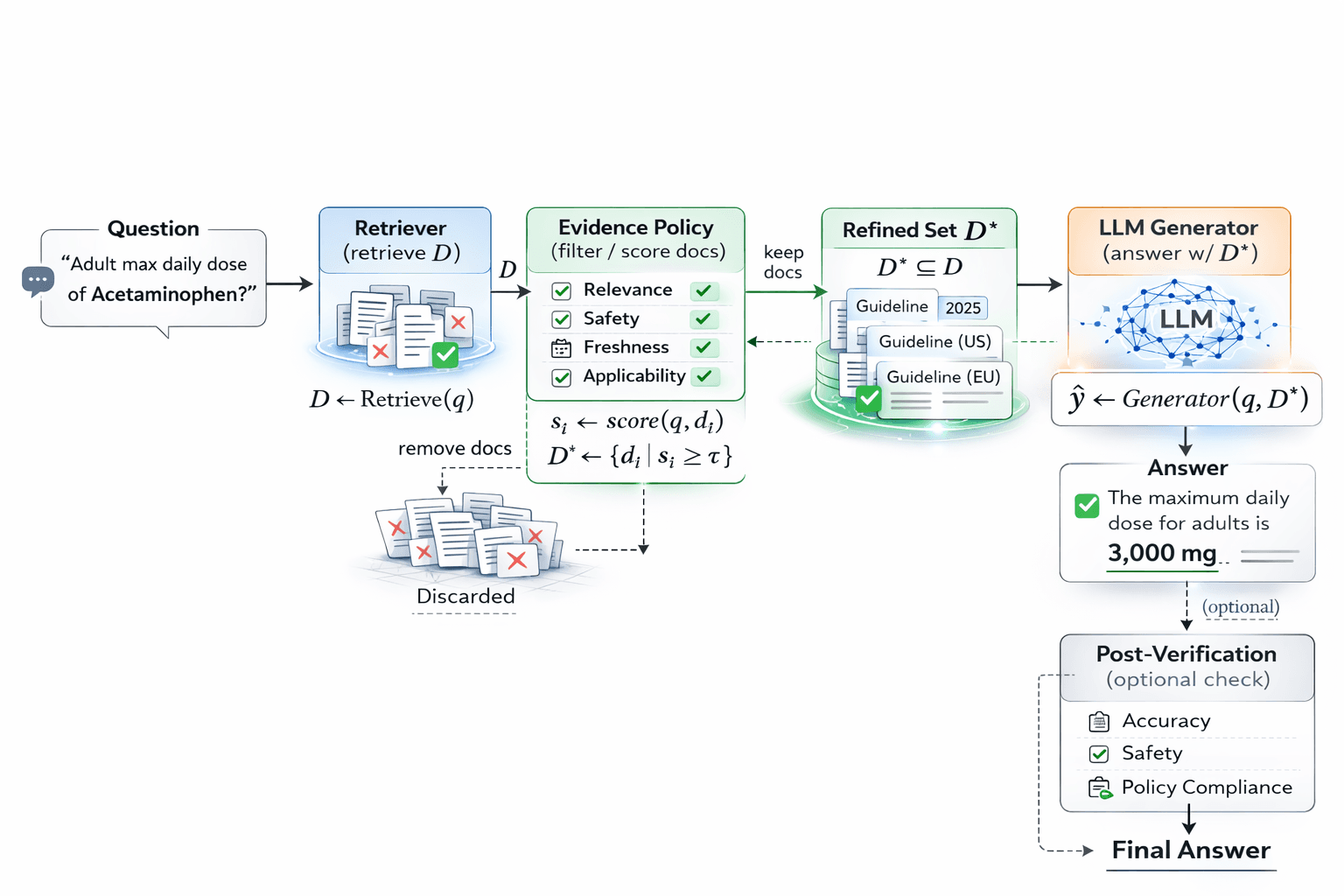
Query → Retrieve → Evidence Policy → Generate
Retrieval is always performed.
But retrieved documents are not passed directly to the generation step.
An Evidence Governance Layer sits in between.
In production, Persly also includes a post-generation verification step that re-evaluates the full answer. However, this post focuses specifically on the retrieval and evidence governance structure, so we omit the details of that downstream stage.
Additionally, filtering out documents that are not directly relevant to the question is not just a matter of accuracy—it is significantly more efficient in terms of token consumption as well.
Including unnecessary documents in the LLM context increases cost and latency while simultaneously raising the risk of reasoning distortion. Persly's Evidence Policy therefore serves a dual role: governing safety and coherence while structurally optimizing compute resource usage.
Evidence Governance Layer
What Model Are We Training?
We do not train a new Foundation LLM for this purpose. What we train is an Evidence Policy:
- Input: query , retrieved document set
- Output: refined document set
- Objective: decide which documents to use and which to discard
In other words, the model Persly builds is not one that decides "whether to retrieve,"
but one that:
Learns the net benefit of retrieved evidence.
How Is the Evidence Policy Trained?
Persly's Evidence Policy is not a simple relevance model. We train it to jointly assess whether a retrieved document is:
- Safe
- Up to date
- Applicable to the patient's condition
- Consistent with other retrieved documents
Training is organized into three stages.
Stage 1: Initial Labeling via Weak Supervision
We first generate initial labels for document inclusion using rule-based signals.
Examples:
- Drop documents that are outdated based on publication date
- Penalize low-authority sources
- Drop documents with jurisdiction mismatch
- Drop population-specific documents matched to general queries
This stage is imperfect, but it provides a stable teacher signal at scale.
Stage 2: Supervised Document Classifier
Next, we train a model that takes (query, document) pairs as input and predicts whether a given document should be used in the generation step.
Input:
Output:
This model is designed to capture not just semantic relevance, but also:
- Applicability
- Safety alignment
- Freshness
- Context match
Stage 3: Answer-Level Counterfactual Calibration
The final stage measures the actual net benefit of each document.
The core idea is simple:
Does the answer improve when we include this document versus when we exclude it?
Procedure:
- Retrieve
D LLM(q, D) → answer_fullLLM(q, D \ {dᵢ}) → answer_minus_i- Compare the two answers on accuracy and safety criteria
If removing a specific document improves the accuracy or safety of the answer, that document is classified as harmful evidence.
Through this process, Persly learns not just relevance, but:
The net benefit of each document.
What It Means to Treat Retrieval as an Expert
The reason Persly calls retrieval an "expert" is straightforward:
- The LLM is a parametric expert
- Retrieval is a non-parametric expert
- The Evidence Policy is a governance layer that controls experts
In healthcare, something matters more than "more documents":
Which documents should be used?
Retrieval is a powerful knowledge augmentation tool, but it can also become a source of contamination.
Persly therefore does not try to reduce retrieval.
Instead,
Persly manages retrieval.
Why Persly Pursues This Direction
Evaluating healthcare agents goes far beyond simple accuracy.
- Reflecting the latest guidelines
- Maintaining jurisdictional consistency
- Verifying applicability to specific patient populations
- Preventing evidence overload
- Managing latency
- Controlling cost
Choosing not to retrieve is difficult to justify in a healthcare setting.
But governing retrieved evidence is structurally safe.
Persly treats retrieval as another expert and builds a structure where a policy layer governs what that expert is allowed to say.
This is the Evidence-Governed RAG that Persly is building.
Ready to try Persly?
Get trustworthy medical answers backed by verified sources. Persly helps patients and caregivers navigate health information with confidence.